Data indexing, simulation, and summary statistics
Contents
3. Data indexing, simulation, and summary statistics#
You should now be able to manipulate 2D arrays of various sizes. In this final NumPy section, we will explore how to do some serious aspects of data handling that are important for reproducible research:
Simulating data - when designing experiments, you can simulate data to plan your analysis correctly.
Data cleaning, and preparation - finding certain cases to extract/outliers to remove
Basic summary statistics - computing the mean, median, standard deviation
These are all essential parts of any reproducible analysis workflow, but you may not have undertaken these steps yourself in the past depending on your research experience.
3.1. Simulating data#
Why would we want to simulate data? One reason is to plan our analyses before we start. In the past, psychologists would throw statistical tests at a dataset they had collected because a particular test ‘fit’ the data.
However, if you have some data in hand to start, you can carefully plan your analysis (perhaps as part of a pre-registration), or use it to highlight issues with your design you might not have foreseen.
3.2. The np.random module#
NumPy has all the tools we need to generate random data, in a submodule called random. This module contains a huge range of possible distributions that you can randomly generate data from - such as the normal distribution, an F distribution, chi-square, and so on.
Most psychological data is normally distributed. How can we make an array of normally distributed data? Using the function normal in the random module of NumPy - np.random.normal()
# Demonstrate use of normal - distribution has a mean of zero and SD of 1
single_int = np.random.normal()
# Pass in dimension values as arguments to create a very long row of random numbers!
lots = np.random.normal(size=1000)
import matplotlib.pyplot as plt
import seaborn as sns
show_fig, ax = plt.subplots(1,1)
sns.histplot(lots, ax=ax, kde=True);
np.random.normal has keyword arguments to create distributions of different widths, centred on different means. The utility of this is obvious - you can generate samples for different variables, as if you had collected the data already.
# Compared to original....
# Same width, different mean
mean2 = np.random.normal(loc=2.0, scale=1, size=1000)
# Different width, same mean
sd2 = np.random.normal(loc=0.0, scale=3, size=1000)
# Different width, different mean
diff = np.random.normal(loc=-10.0, scale=0.5, size=1000)
# Illustrate
show_fig
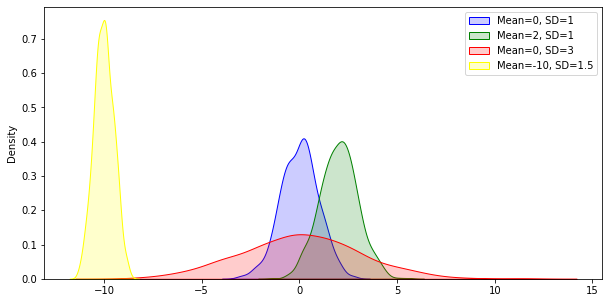
There are other useful functions for generating data - for example, np.random.randint can generate datasets of a specific size and shape, of numbers between a certain bound.
# Generate some fake personality data with `randint`, for 100 participants
big5 = np.random.randint(low=1, high=6, size=(100, 5))
print(big5[:5, :])
[[2 3 4 5 1]
[5 2 2 3 1]
[1 3 1 1 3]
[2 4 5 4 5]
[4 2 2 2 2]]
3.3. Data cleaning and preparation#
Almost all datasets require some form of cleaning - removal of participants who didn’t complete all the trials, variables with too many missing values, or scores outside acceptable ranges. You may not have had the opportunity to do this yourself at this stage, or maybe you did it manually in Excel or other data pipelines.
As you might expect, Python and NumPy can find data that fits a certain critera and lets you specify exactly what you want to do to it. You’ve already used the basic tools of this approach before - logicals. The difference now is that these logicals are computed for every value in an array, whatever its shape, giving you wide flexibility. In fact, most operations return a Boolean array, sometimes known as a ‘mask’, where your conditional is true/false.
# An example of NumPy boolean logic
toy = np.random.randint(low=1, high=11, size=(10, 4))
print(toy)
[[ 6 10 8 6]
[ 9 5 3 7]
[ 5 7 7 8]
[ 2 4 5 5]
[ 1 8 2 8]
[ 6 2 5 4]
[ 8 5 5 10]
[10 3 1 10]
[ 1 9 6 5]
[ 3 9 1 5]]
# Find scores above 6
above6 = toy > 6
print(np.column_stack((toy, above6)))
[[ 6 10 8 6 0 1 1 0]
[ 9 5 3 7 1 0 0 1]
[ 5 7 7 8 0 1 1 1]
[ 2 4 5 5 0 0 0 0]
[ 1 8 2 8 0 1 0 1]
[ 6 2 5 4 0 0 0 0]
[ 8 5 5 10 1 0 0 1]
[10 3 1 10 1 0 0 1]
[ 1 9 6 5 0 1 0 0]
[ 3 9 1 5 0 1 0 0]]
Now that we have a Boolean array, or a masked array, we can use it to extract values in our array through array indexing. Let’s say we want all the values above 5.
# Use the mask array
extract = toy[above6]
print(extract)
[10 8 9 7 7 7 8 8 8 8 10 10 10 9 9]
Since the shape of the original array could not be preserved after indexing, NumPy collapsed it into a vector.
Also remember you can negate Booleans with ~. So, we can easily get all values not less than 6:
extract2 = toy[~above6]
print(extract2)
[6 6 5 3 5 2 4 5 5 1 2 6 2 5 4 5 5 3 1 1 6 5 3 1 5]
3.4. Building complexity with Boolean indexing - .all() and .any()#
Getting the actual numbers that fit a certain criteria is clearly simple. However, sometimes we need more complex indexing.
Imagine you have data and someone has entered in some out-of-range values. This means they were likely not paying attention, and you can’t trust their data on the other trials. How can we remove them, and just analyse the rest of the data?
# First, make a simple dataset
removals = np.random.randint(low=3, high=21, size=(15, 4))
# Here, we generate a 'mask array' using random.choice which chooses elements from a list at random and generates a specific shape, and probabilites
inds = np.random.choice([True, False], p=[0.1, 0.9], size=removals.shape)
# Now place the 'mask' over 'removals' and alter the numbers by replacing with a high number
removals[inds] = 999
print(removals)
[[ 16 9 4 3]
[ 11 7 17 5]
[ 11 17 10 9]
[ 3 4 17 18]
[ 9 3 16 16]
[ 9 19 13 11]
[ 4 13 7 17]
[999 3 12 19]
[ 6 17 9 5]
[ 8 5 19 11]
[ 8 13 10 15]
[ 11 11 16 5]
[ 14 7 8 9]
[999 16 3 999]
[ 7 15 999 999]]
# To find those erroneous participants is easy - create a new mask array
mask = removals > 20
print(mask)
[[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[ True False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[ True False False True]
[False False True True]]
Now we have our mask, how can we use it to remove the participants who have made an error and given ‘999’ as a response? We already know that subsetting the current ‘mask’ array will return a single vector, but what we want to do is completely remove the rows that contain problematic entries.
The solution is to use the array methods of .any() and .all(). These powerful methods allow you to identify which rows or columns match a condition.
# Demonstrate any on mask array
# Moving across columns (axis 1), what rows have ANY values above 20?
remove_rows = mask.any(axis=1)
# Now use remove_rows to clean the data!
clean = removals[~remove_rows, :]
print(clean)
[[16 9 4 3]
[11 7 17 5]
[11 17 10 9]
[ 3 4 17 18]
[ 9 3 16 16]
[ 9 19 13 11]
[ 4 13 7 17]
[ 6 17 9 5]
[ 8 5 19 11]
[ 8 13 10 15]
[11 11 16 5]
[14 7 8 9]]
# The reverse is easily done - what if we wanted to remove any column with a True?
remove_cols = mask.any(axis=0)
# Empty!!
print(removals[:, ~remove_cols])
[[ 9]
[ 7]
[17]
[ 4]
[ 3]
[19]
[13]
[ 3]
[17]
[ 5]
[13]
[11]
[ 7]
[16]
[15]]
These removal operations are carried out in steps above, but once you are comfortable with them mentally you can do the operations in a single line of code.
clean_quick = removals[~(removals > 20).any(axis=1), :]
print(clean_quick)
[[16 9 4 3]
[11 7 17 5]
[11 17 10 9]
[ 3 4 17 18]
[ 9 3 16 16]
[ 9 19 13 11]
[ 4 13 7 17]
[ 6 17 9 5]
[ 8 5 19 11]
[ 8 13 10 15]
[11 11 16 5]
[14 7 8 9]]
To quickly demonstrate, .all() works in the exact same way:
# Set a row to be all 999 in removals
removals[5,:] = 999
print(removals)
[[ 16 9 4 3]
[ 11 7 17 5]
[ 11 17 10 9]
[ 3 4 17 18]
[ 9 3 16 16]
[999 999 999 999]
[ 4 13 7 17]
[999 3 12 19]
[ 6 17 9 5]
[ 8 5 19 11]
[ 8 13 10 15]
[ 11 11 16 5]
[ 14 7 8 9]
[999 16 3 999]
[ 7 15 999 999]]
# This time in one line and specifying exactly to match to the number 999
drop = removals[~(removals == 999).all(axis=1), :]
print(drop)
[[ 16 9 4 3]
[ 11 7 17 5]
[ 11 17 10 9]
[ 3 4 17 18]
[ 9 3 16 16]
[ 4 13 7 17]
[999 3 12 19]
[ 6 17 9 5]
[ 8 5 19 11]
[ 8 13 10 15]
[ 11 11 16 5]
[ 14 7 8 9]
[999 16 3 999]
[ 7 15 999 999]]
3.5. More complex Booleans#
As with lists, you are able to build more complex conditions that allow for greater flexibility in accessing your data. However, unlike with lists, you will use the bitwise operators - & and |. These allow for comparisons of individual elements of an array. Using these also requires a little extra skill compared to and and or.
# Make some more data
a = np.random.randint(low=3, high=12, size=(1, 10))
b = np.random.randint(low=5, high=15, size=(1, 10))
How could we find the locations where a is greater than 5, AND b is less than 9? The obvious solution is:
get_vals = a > 5 and b < 9
This won’t work! In fact, neither will:
get_vals = a > 5 & b < 9
This is due to something called operator precedence - not something you need to know for this course, but how it impacts how you query data is important.
To carry out these complex conditions with arrays, use the following format (similar to how complex comparisons are performed with single integers with regular and and or):
get_vals = (a > 5) & (b < 9)
print(get_vals)
[[ True False False False False True False False True False]]
The | operator functions in much the same way.
or_vals = (a > 5) | (b < 9)
print(or_vals)
[[ True True False True False True False False True True]]
NumPy offers flexibility in how you want to achieve your goals of Boolean comparisons. The functions np.logical_and and np.logical_or may be easier to interpret for you - use whatever works.
# Demonstrate function versions of and/or
func_and = np.logical_and(a > 5, b < 9)
print(np.all(get_vals == func_and))
func_or = np.logical_or(a > 5, b < 9)
print(np.all(or_vals == func_or))
True
True
3.6. The power of np.where#
One of the most powerful functions available to you is np.where. This function returns the indices (locations) of values that match your query - and with those, you are able to modify an array or carry out other computations. For example:
# Demonstrate np.where
data = np.random.randint(low=1, high=15, size=(4,5))
print(data)
[[12 3 9 14 11]
[ 3 11 10 14 8]
[11 10 8 5 2]
[11 1 8 14 5]]
# Get indices with np.where of values less than 5 or above 10
inds = np.where((data < 5) | (data > 10))
print(inds)
(array([0, 0, 0, 0, 1, 1, 1, 2, 2, 3, 3, 3]), array([0, 1, 3, 4, 0, 1, 3, 0, 4, 0, 1, 3]))
# Use indices to alter the array
data[inds] = 30
print(data)
[[30 30 9 30 30]
[30 30 10 30 8]
[30 10 8 5 30]
[30 30 8 30 5]]
But np.where has additional functionality. Aside from its first argument (the conditional), it also has an additional two arguments that specify what you want if the conditions are met (first additional argument) and if they are not met (second additional argument).
# Demonstrate np.where additional args
data = np.random.randint(low=1, high=15, size=(4,5))
cool = np.where(data == 5, 9999, 1111)
print(data)
print(cool)
[[ 7 14 9 13 13]
[ 9 10 3 2 9]
[ 6 5 11 3 4]
[ 6 12 3 12 10]]
[[1111 1111 1111 1111 1111]
[1111 1111 1111 1111 1111]
[1111 9999 1111 1111 1111]
[1111 1111 1111 1111 1111]]
data = np.random.randint(low=1, high=15, size=(4,5))
cool = np.where(data > 5, data, -1)
print(data)
print(cool)
[[12 12 9 7 11]
[ 6 7 9 12 13]
[12 11 2 11 4]
[ 8 12 8 1 13]]
[[12 12 9 7 11]
[ 6 7 9 12 13]
[12 11 -1 11 -1]
[ 8 12 8 -1 13]]
np.where breakdown:
np.where(conditional_statement, a, b)
conditional_statement - this is a conditional statement that can be as simple or as complex as you like.
a - A value you would like returned where the condition is True. This can be an integer, or if you pass it an array, it will be the values of that array where the condition is True - shapes must fit!
b - A value you would like returned where the condition is False. Same rules apply as above.
3.7. NaN#
Sometimes, participants dont respond at all, never mind responding strangely. In order to fill in these gaps, there is a special data type called NaN - Not a Number. This is a simple placeholder for missing values in an array, and has special functions associated with finding it, such as np.isna().
# Add some NaN's to a dataset - only works with floats!
removals = removals.astype('float')
removals[(removals == 999)] = np.NaN
print(removals)
[[16. 9. 4. 3.]
[11. 7. 17. 5.]
[11. 17. 10. 9.]
[ 3. 4. 17. 18.]
[ 9. 3. 16. 16.]
[nan nan nan nan]
[ 4. 13. 7. 17.]
[nan 3. 12. 19.]
[ 6. 17. 9. 5.]
[ 8. 5. 19. 11.]
[ 8. 13. 10. 15.]
[11. 11. 16. 5.]
[14. 7. 8. 9.]
[nan 16. 3. nan]
[ 7. 15. nan nan]]
# Demonstrate isnan
nan_mask = np.isnan(removals)
# This won't be helpful!
invalid_nan = removals == np.nan
print(nan_mask, invalid_nan)
[[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[ True True True True]
[False False False False]
[ True False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[ True False False True]
[False False True True]] [[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]
[False False False False]]
# With isnan, remove
print(removals[~np.isnan(removals).any(axis=1), :])
[[16. 9. 4. 3.]
[11. 7. 17. 5.]
[11. 17. 10. 9.]
[ 3. 4. 17. 18.]
[ 9. 3. 16. 16.]
[ 4. 13. 7. 17.]
[ 6. 17. 9. 5.]
[ 8. 5. 19. 11.]
[ 8. 13. 10. 15.]
[11. 11. 16. 5.]
[14. 7. 8. 9.]]
3.8. Basic summary statistics#
Once you have your data, you almost always want to compute some kind of descriptive statistics with it. For example, what is the mean score per participant across trials? What’s the standard deviation for a certain variable, so we can remove participants who are above or below that? NumPy has a range of methods that can compute statistics on data. The most common used are .mean(), .std(), and .median().
Each method has certain inputs - the most important of which is the ‘axis’ argument, which indicates which axis to compute the statistic across - zero means ‘across the rows’, or the first dimension, and 1 means ‘across the columns’, or the second dimension. Higher dimensional arrays also work the same.
# Demonstrate use of summary stats - this line is generating data, can you figure out how?
data = np.column_stack([np.random.normal(*stats) for stats in [(4, 1, 20), (3, 5, 20), (6, 2, 20), (3, 2, 20)]])
print(data)
[[ 4.40549788 -5.8945876 5.27231756 2.82950263]
[ 3.26521476 13.68067485 5.27149178 6.66658814]
[ 3.97369132 10.55133762 6.56577065 0.905936 ]
[ 3.90003694 0.75157498 6.16324889 1.43627219]
[ 2.75192226 -4.38672928 7.53873378 -2.59407701]
[ 4.49718161 -2.98984692 7.55264833 4.01250152]
[ 2.72249929 -2.38705724 6.14342985 3.16698008]
[ 2.84739553 -0.28597373 5.14789201 3.89497622]
[ 4.01820666 2.49859376 6.67348028 3.56482336]
[ 2.65364355 13.51736722 7.271999 1.9993469 ]
[ 3.83527756 8.37564678 7.1858053 6.7891327 ]
[ 5.47145651 9.04861772 6.98838738 3.54553964]
[ 4.86727095 7.23706809 5.72740921 -2.09405354]
[ 3.24015722 4.6119196 9.00041547 5.95890339]
[ 4.38931701 3.65456654 5.85292087 -0.96364816]
[ 5.53144377 2.20107347 6.53616412 1.99448352]
[ 3.13322738 0.63694941 6.88851194 1.64227514]
[ 2.00327349 0.01897242 3.15181342 3.08411176]
[ 4.42070816 6.37976071 9.90523605 2.49716886]
[ 4.97523511 18.23705147 3.60636425 0.87885249]]
# What is mean and standard deviation for the whole data? Call methods with NO arguments
grand_mean, grand_std = data.mean(), data.std()
print(grand_mean, grand_std)
4.250241160241453 3.8050405976178907
# Summary statistics per VARIABLE - so across rows, one score per column
var_mean = data.mean(axis=0)
print(var_mean)
[3.84513285 4.27284899 6.42220201 2.46078079]
# Summary statistics per PARTICIPANT - across columns, one score per row
ppt_mean = data.mean(axis=1)
print(ppt_mean)
[1.65318261 7.22099238 5.4991839 3.06278325 0.82746244 3.26812113
2.411463 2.90107251 4.18877601 6.36058917 6.54646559 6.26350031
3.93442368 5.70284892 3.23328907 4.06579122 3.07524097 2.06454277
5.80071845 6.92437583]
# Combined
descriptives = np.column_stack((data.mean(1), data.std(1)))
print(descriptives)
[[1.65318261 4.4448268 ]
[7.22099238 3.92057364]
[5.4991839 3.5386056 ]
[3.06278325 2.13898941]
[0.82746244 4.68079684]
[3.26812113 3.8595346 ]
[2.411463 3.06679485]
[2.90107251 2.01222435]
[4.18877601 1.53695171]
[6.36058917 4.60467208]
[6.54646559 1.67063513]
[6.26350031 2.01847615]
[3.93442368 3.58242232]
[5.70284892 2.13274976]
[3.23328907 2.54905023]
[4.06579122 2.00114764]
[3.07524097 2.37397634]
[2.06454277 1.26587819]
[5.80071845 2.73862296]
[6.92437583 6.6957698 ]]